

Minimax M2.7 se vuelve OpenSource y Unsloth ha publicado la versión optimizada de MiniMax M2.7, el modelo de lenguaje de 230.000 millones de parámetros que, gracias a la cuantización dinámica a 4 bits, reduce su tamaño de 457GB a solo 108GB. Esto significa que puedes ejecutarlo en un Mac con 128GB de memoria unificada, o en cualquier equipo con una GPU de 16GB y 96GB de RAM.
De 457GB a 108GB: así funciona la cuantización de Unsloth
MiniMax M2.7 en su formato original bf16 sin cuantizar necesita 457GB de memoria. Eso está fuera del alcance de cualquier consumidor. Pero Unsloth aplica su tecnología Dynamic 4-bit GGUF, que reduce el modelo a 108GB (un 60% menos) manteniendo la mayor parte de la calidad del modelo original.
La clave de Unsloth Dynamic 2.0 es que las capas más importantes se upcastean a bits más altos (8 o 16 bits), mientras que las menos críticas se cuantizan agresivamente. El resultado es un equilibrio entre tamaño y precisión que supera a las cuantizaciones tradicionales.
Rendimiento en hardware real
Los números que comparte Unsloth son claros:
- Mac con memoria unificada de 128GB: más de 15 tokens/segundo
- Equipos con GPU de 16GB + 96GB de RAM: más de 25 tokens/segundo
- Para quienes necesiten más precisión, la versión Q8_0 (8 bits) ocupa 243GB y funciona en dispositivos de 256GB de RAM
Configuración recomendada
MiniMax recomienda estos parámetros para obtener los mejores resultados:
- Temperatura: 1.0
- top_p: 0.95
- top_k: 40
- Ventana de contexto: hasta 196.608 tokens
⚠️ Nota importante: Unsloth advierte de que no se debe usar CUDA 13.2 para ejecutar ningún modelo, ya que puede producir salidas incoherentes o de baja calidad. NVIDIA está trabajando en una corrección.
Cómo ejecutar MiniMax M2.7 en tu equipo
Hay dos formas principales de ejecutar el modelo:
Opción 1: Unsloth Studio
La forma más sencilla. Unsloth Studio es una interfaz web de código abierto que permite buscar, descargar y ejecutar modelos GGUF localmente en MacOS, Windows y Linux. Solo necesitas instalar el programa, buscar MiniMax M2.7, descargar la versión UD-IQ4_XS y chatear con el modelo desde el navegador.
Opción 2: llama.cpp
Para quienes prefieran la línea de comandos o necesiten desplegar el modelo en producción, Unsloth proporciona las instrucciones para compilar llama.cpp y ejecutar el modelo directamente. También se puede usar llama-server para desplegarlo como una API compatible con la biblioteca OpenAI.
Posiciones en benchmarks
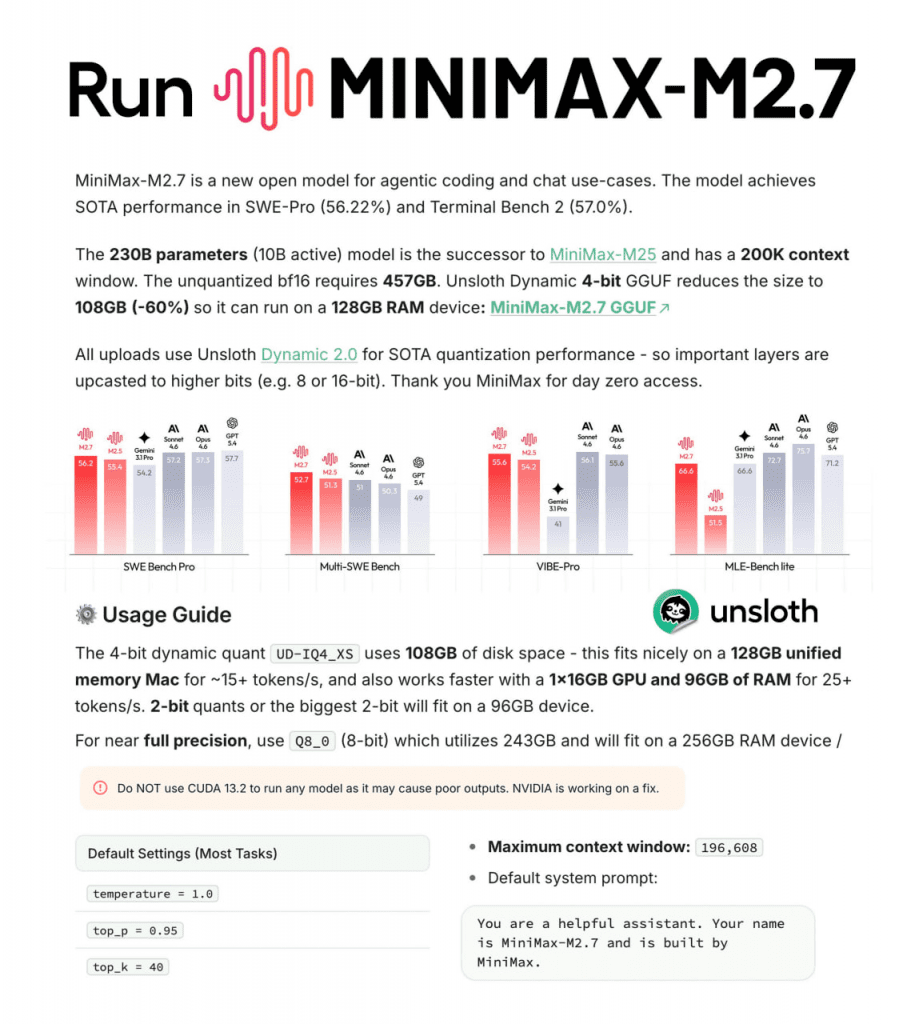
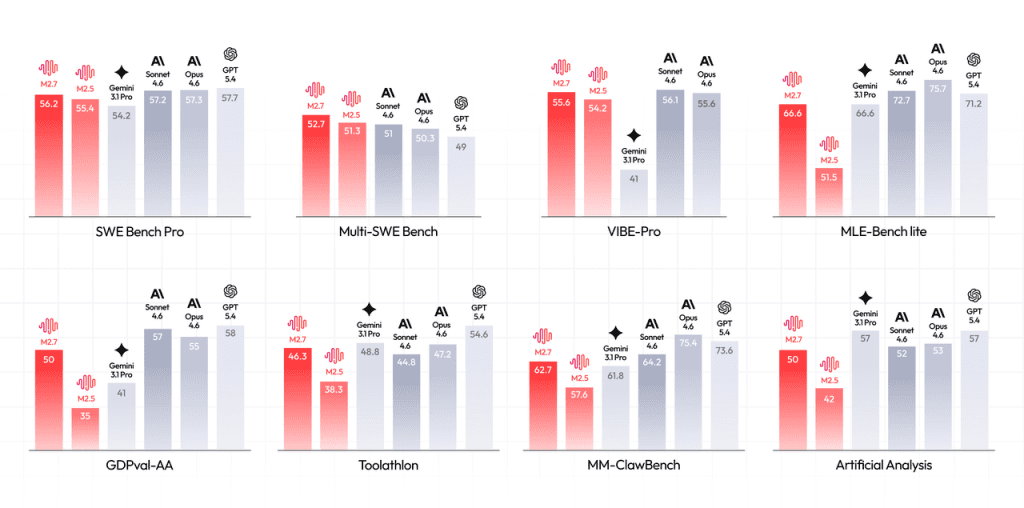
En términos de rendimiento bruto, MiniMax M2.7 obtiene un 56,22% en SWE-Pro, superando a GPT-4o y Claude 3.5 Sonnet en tareas de ingeniería de software. En Terminal Bench 2 alcanza el 57,0%.
Según los benchmarks de cuantización de Unsloth, la mejor relación calidad-tamaño la ofrece el cuant UD-Q4_K_XL, que pierde solo 6 puntos respecto al modelo original con un 22,8% más de errores. Las versiones Q4 de Unsloth superan claramente a las cuantizaciones no optimizadas de otros proveedores, incluso cuando son 8GB más pequeñas.
Disponibilidad
El modelo ya está disponible en Hugging Face y las instrucciones completas de instalación están en la documentación oficial de Unsloth.
MiniMax M2.7 era ya uno de los modelos más potentes para codificación y tareas de agente. Ahora, gracias a Unsloth, también es uno de los más accesibles.

Creador de contenido especializado en realidad virtual, realidad aumentada, inteligencia artificial y tecnologías inmersivas. Noticias, análisis y opiniones sobre el mundo de la VR/AR/MR/IA sin perder de vista lo que realmente importa: que la tecnología tenga sentido para quien la usa.
Relacionadas
John Ternus, el nuevo CEO de Apple podría frenar Vision Pro
Bigscreen presenta el nuevo Halo Mount para Beyond 2
Meta Horizon OS 2.3 llega a Quest con pequeñas mejoras